Where can we find worlds best coffee?

To start off the series of posts on my website, I decided to have a look at coffee. While I really enjoy coffee, I am still trying to find the one that I like the best so I hope that, by looking at reviews of many different coffee, I will be able to find new, interesting coffee to try.
The data I will be looking at comes from Coffee Quality Database created by James LeDoux. This data appeared in Kaggle and #TidyTuesday.
Description of the data
Obtained dataset contains reviews of 1312 arabica and 28 robusta coffee beans from the Coffee Quality Institute’s reviewers. For each coffee, various features are provided like:
- Quality scores which contain information like Flavor, Acidity, Sweetness…
- Bean metadata that describes beans colour, processing type and species.
- Farm metadata which provides infomation as the country of origin, altitude at which coffee was grown, the owner of the farm…
In total, for each bean we have 43 descriptors.
The first question I wanted to address was: What are the carachteristics of the best scoring coffee and which country has the best scoring coffee.
I decided then to compare coffee ratings across countries and the associated density of cups rated. Among the main findings it shows that one Ethiopian coffee came to be the best ranked and also that this country’s coffees are the best ranked while Haitian coffees show one of the widest range of ratings. Colombian coffee display a moderately good ratings and a very narrow range.
raw_arabica <- read_csv("https://raw.githubusercontent.com/jldbc/coffee-quality-database/master/data/arabica_data_cleaned.csv") %>%
janitor::clean_names()
raw_robusta <- read_csv("https://raw.githubusercontent.com/jldbc/coffee-quality-database/master/data/robusta_data_cleaned.csv",
col_types = cols(
X1 = col_double(),
Species = col_character(),
Owner = col_character(),
Country.of.Origin = col_character(),
Farm.Name = col_character(),
Lot.Number = col_character(),
Mill = col_character(),
ICO.Number = col_character(),
Company = col_character(),
Altitude = col_character(),
Region = col_character(),
Producer = col_character(),
Number.of.Bags = col_double(),
Bag.Weight = col_character(),
In.Country.Partner = col_character(),
Harvest.Year = col_character(),
Grading.Date = col_character(),
Owner.1 = col_character(),
Variety = col_character(),
Processing.Method = col_character(),
Fragrance...Aroma = col_double(),
Flavor = col_double(),
Aftertaste = col_double(),
Salt...Acid = col_double(),
Balance = col_double(),
Uniform.Cup = col_double(),
Clean.Cup = col_double(),
Bitter...Sweet = col_double(),
Cupper.Points = col_double(),
Total.Cup.Points = col_double(),
Moisture = col_double(),
Category.One.Defects = col_double(),
Quakers = col_double(),
Color = col_character(),
Category.Two.Defects = col_double(),
Expiration = col_character(),
Certification.Body = col_character(),
Certification.Address = col_character(),
Certification.Contact = col_character(),
unit_of_measurement = col_character(),
altitude_low_meters = col_double(),
altitude_high_meters = col_double(),
altitude_mean_meters = col_double()
)) %>%
janitor::clean_names() %>%
rename(acidity = salt_acid, sweetness = bitter_sweet,
aroma = fragrance_aroma, body = mouthfeel,uniformity = uniform_cup)
all_ratings <- bind_rows(raw_arabica, raw_robusta) %>%
select(-x1) %>%
select(total_cup_points, species, everything())
## rename Tanzania
all_ratings$country_of_origin[all_ratings$country_of_origin == "Tanzania, United Republic Of"] <- "Tanzania"Initial look at data
countries <- data.frame(country_of_origin=unique(all_ratings$country_of_origin))
countries$continent_region <- c("Africa", "Central America", rep("South America", 2), rep("North America", 2), rep("Asia", 2), rep("Central America", 2), "Africa", "Central America", "Asia", "Central America", rep("Africa", 2), "Asia", "South America", "Central America", "Oceania", "Central America", "Asia", "South America", rep("North America", 2), "Africa", rep("Asia", 2), rep("Africa", 2), "Asia", "Africa", "Asia", rep("Africa", 2), NA, "Asia")
countries$continent_region <- factor(countries$continent_region)
ord <- all_ratings %>%
left_join(countries) %>%
group_by(continent_region, country_of_origin) %>%
summarise(n = n()) %>%
arrange(continent_region, desc(n))
all_ratings$country_of_origin <- factor(all_ratings$country_of_origin, levels = ord$country_of_origin)
all_ratings %>%
left_join(countries) %>%
drop_na(any_of("country_of_origin")) %>%
ggplot(aes(country_of_origin, fill=continent_region))+
geom_histogram(stat = "count")+
theme_minimal()+
scale_fill_brewer(palette = "Dark2")+
theme(axis.text.x=element_text(angle=60, hjust=1, vjust = 1.05))+
ggtitle("Americas have the most coffee beans in the dataset")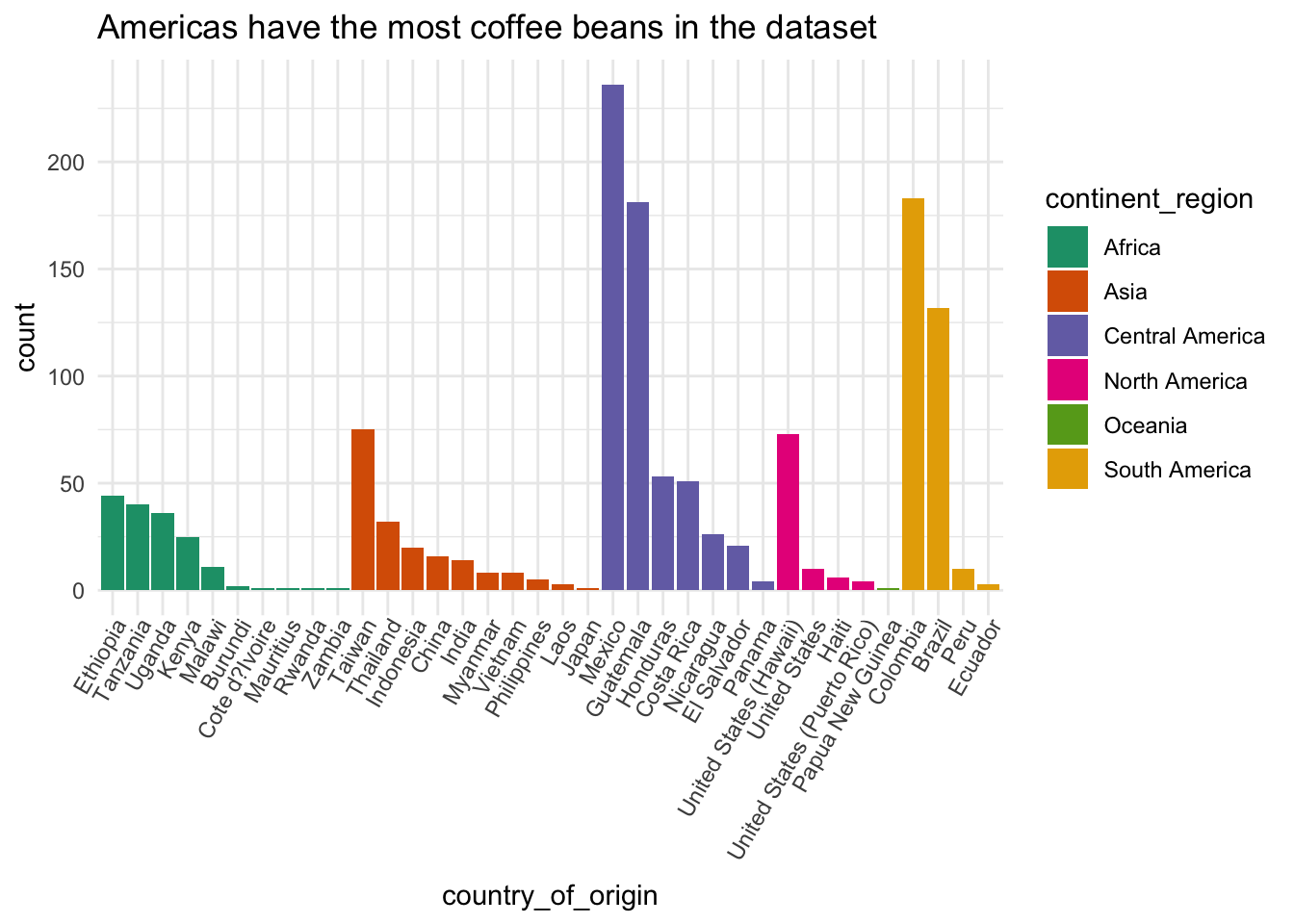
all_ratings %>%
drop_na(any_of("country_of_origin")) %>%
filter(!country_of_origin %in% c("Papua New Guinea", "Japan", "Zambia", "Rwanda", "Mauritius", "Cote d?Ivoire", "Burundi")) %>%
mutate(country_of_origin = fct_reorder(country_of_origin, total_cup_points, median)) %>%
ggplot(aes(x = total_cup_points, y = country_of_origin, fill = stat(x))) +
geom_density_ridges_gradient(show.legend = T, alpha = .5, point_alpha = 0.2, jittered_points = TRUE) +
scale_fill_viridis_c(alpha=0.75, rescaler = function(x, to = c(0, 1), from = NULL) {
ifelse(x<92,
scales::rescale(x, to = to, from = c(75, 92)), 1)}) +
ylab("") +
xlab("Total cup points") +
coord_cartesian(xlim=c(58, 92))+
labs(title = "Distribution of coffee ratings across countries",
subtitle = "Although Ethiopian coffee has best scoring coffee \nUS coffee has the highest median of coffee scores",
fill = "Total points awarded") +
theme_minimal() +
theme(plot.title = element_text(size = 16, face = "bold"),
plot.subtitle = element_text(size = 12),
axis.title.x = element_text(size = 14),
axis.title.y = element_text(size = 14),
axis.text.y = element_text(size = 14),
plot.caption = element_text(size = 12))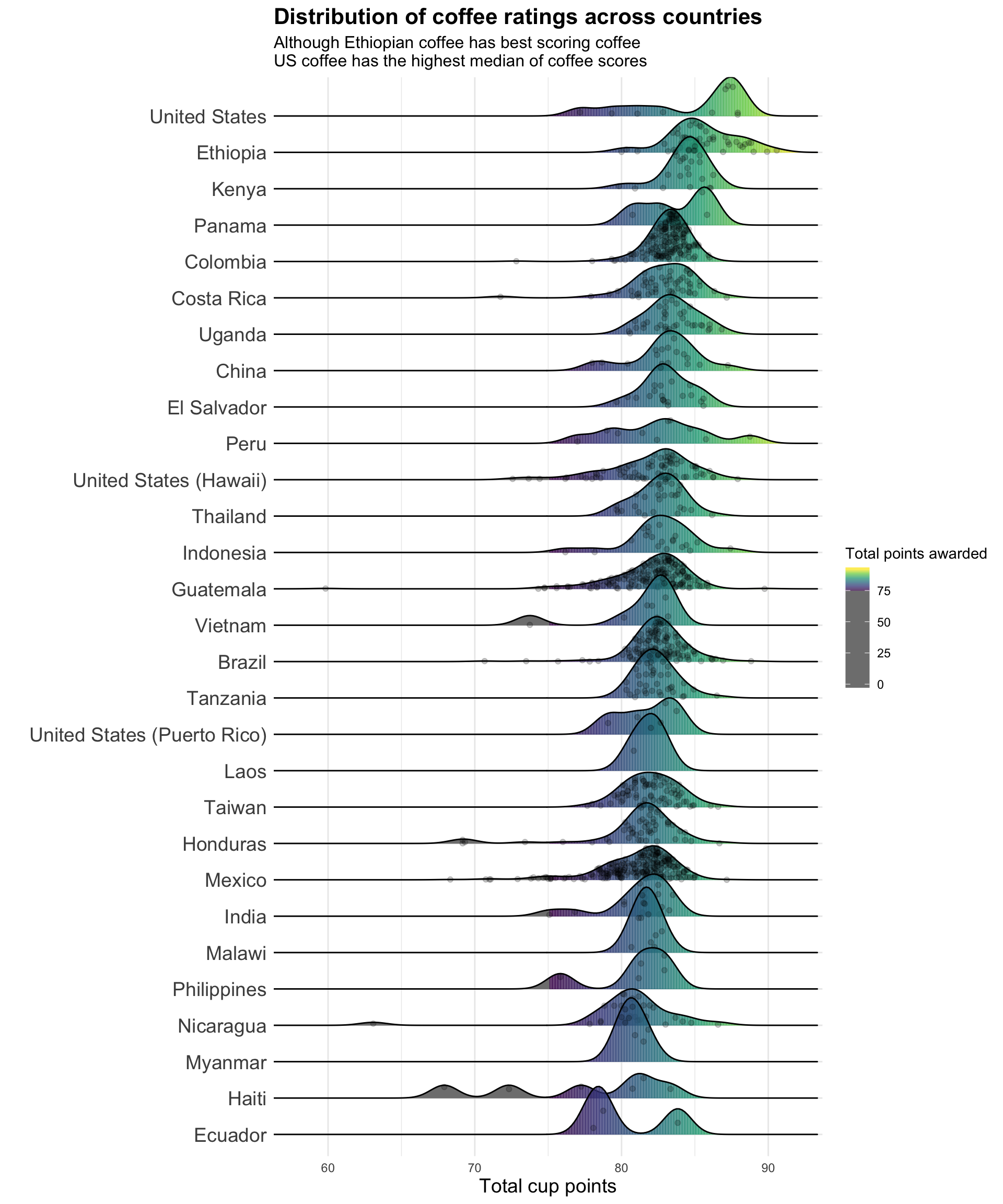
How correlated are different coffee taste characteristics with the final score
I am not a fan of acidic coffee so I am wondering if acidity is a feature of higher scoring coffee. Also it would be interesting to see if different continents have less acidic coffee.
all_ratings %>%
left_join(countries) %>%
ggplot(aes(x=total_cup_points, y=acidity, col=continent_region))+
geom_point()+
theme_minimal()+
scale_color_brewer(palette = "Dark2")+
coord_cartesian(xlim=c(58, 92), ylim=c(5, 8.5))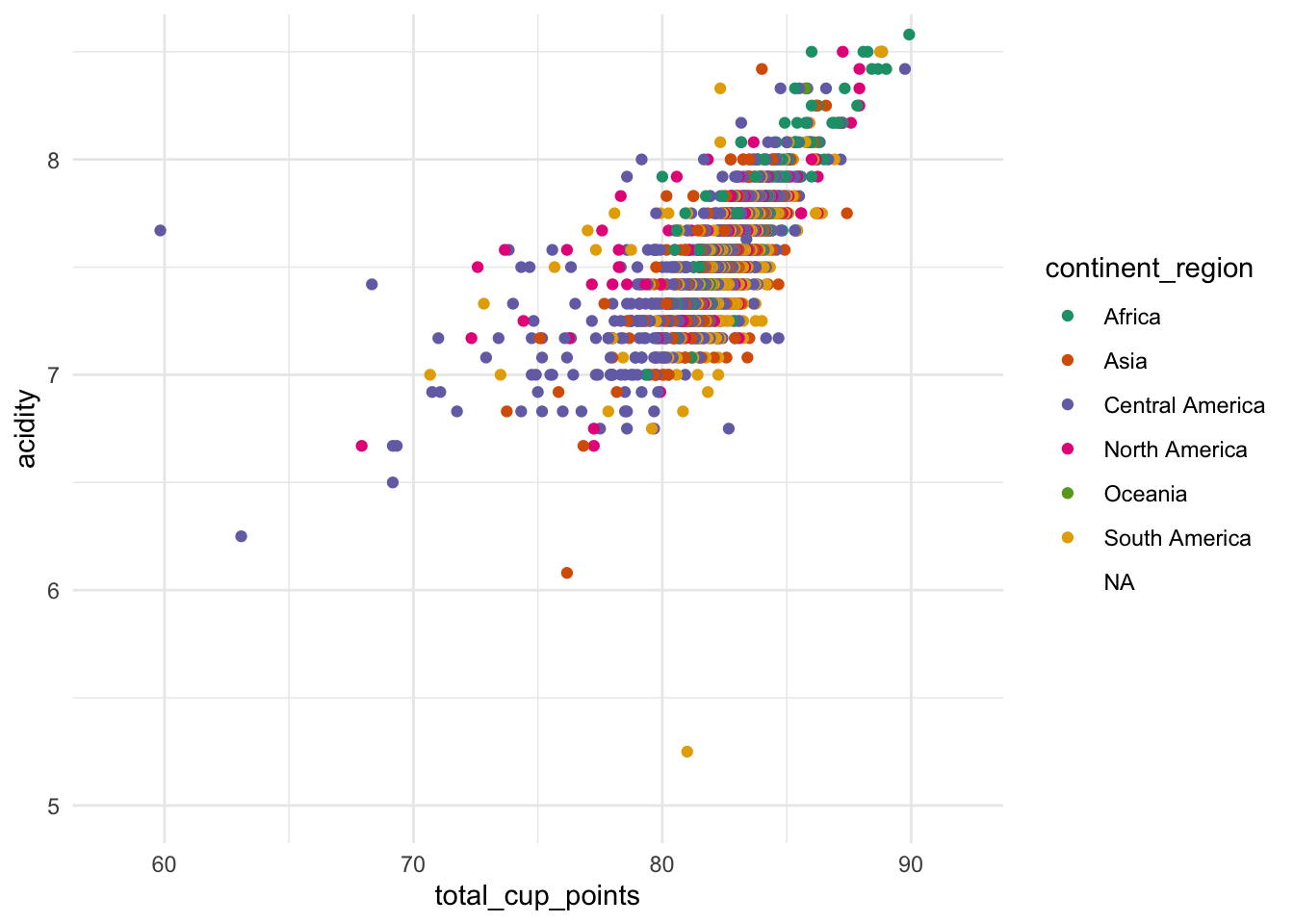
all_ratings %>%
drop_na(any_of("country_of_origin")) %>%
left_join(countries) %>%
ggplot(aes(x=continent_region, y=acidity, col=continent_region))+
geom_boxplot()+
theme_minimal()+
scale_color_brewer(palette = "Dark2")+
theme(axis.text.x=element_text(angle=60, hjust=1, vjust = 1.05))+
coord_cartesian(ylim=c(5, 8.5))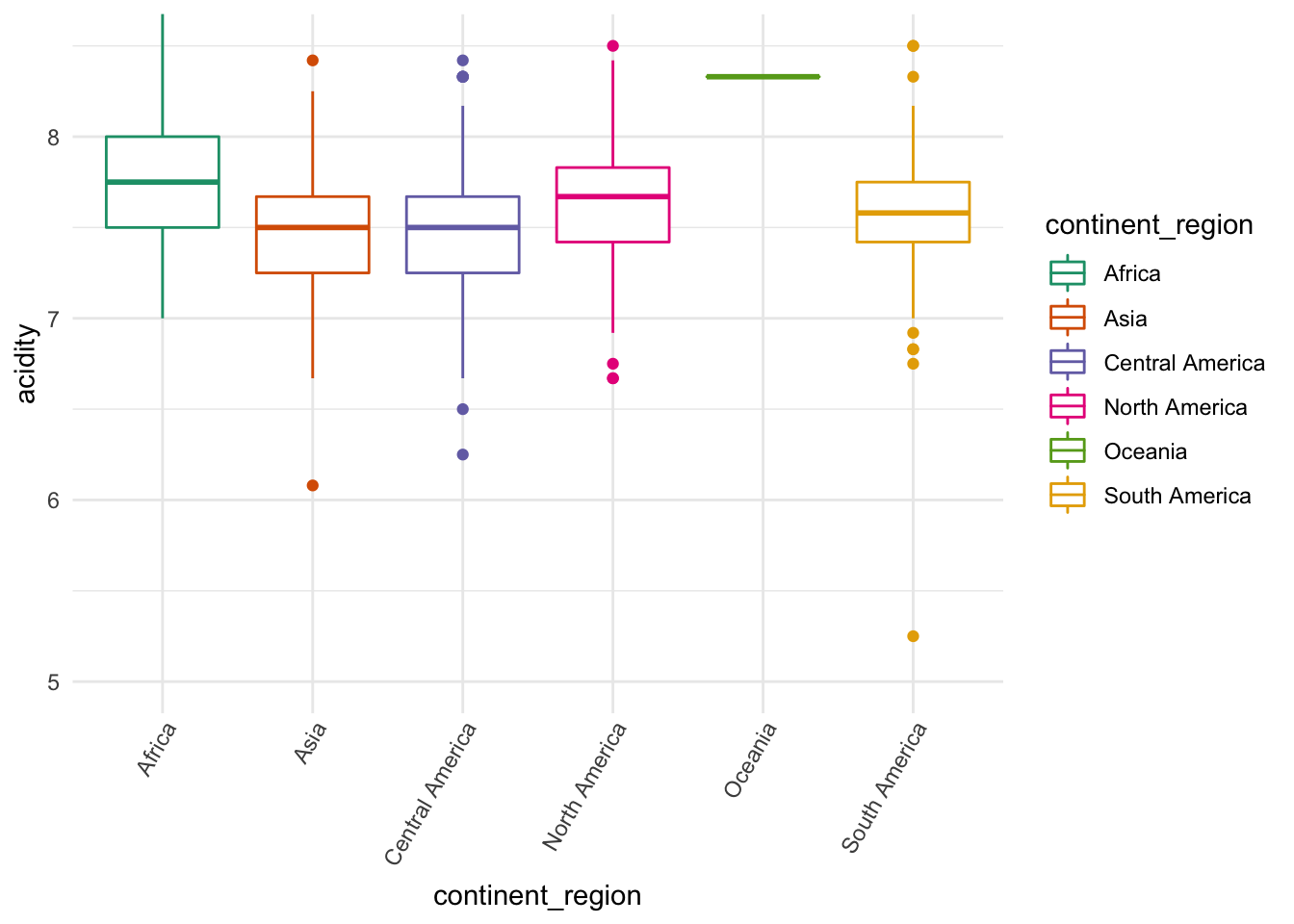 Asian and central American coffee seems to have less acidic coffee.
Asian and central American coffee seems to have less acidic coffee.
Some interesting facts
Fairtrade coffee costs more, but coffee farmers spend at least 25% of this Fairtrade Premium to enhance productivity and quality. Over the last three years, Fairtrade-certified coffee products have won 28 Great Taste Awards.
Dunja Vucenovic
Bioinformatics Scientist
I am interested in genomics, big data analysis and machine learning.